지도학습(분류): 붓꽃데이터 분석

지도학습(분류): 붓꽃데이터 분석
target 값이 이산적인 값이거나 범주형 데이터일때 수행할 수 있다. 즉 이 데이터가 A에 속하느냐 또는 B에 속하느냐를 판별하는 것이다.
Orange에서 제공하고 있는 tab data set

우리가 앞전에 사용했던 housing data는 tab데이터로 구별되어 있다.
여기에는 이 속성의 이름을 나타내는 행이 가장 먼저 있고, 그 다음 속성의 타임, 종류를 나타내는 행이 있다. 그리고 나머지는 데이터들이다.
속성에서 c는 연속적인 숫자, d는 이산적/ 범주형 데이터, s는 string(문자열)을 의미한다.
우리가 앞 전에 target값은 mdev 중앙값으로, 이런 경우에 regression을 수행한다.
그리고 kinds(종류)에는 class 또는 meta를 기입할 수 있다. 우리들이 tab형식의 데이터 셋을 만들때에도 이런 형식으로 작성을 해주면 된다. class는 우리가 목표로 하는 target값이 mdev, 즉 주택가격의 중간값을 나타낸다.
meta는 실제 학습에 참여하지는 않지만, 우리가 값을 참고하기 위해서 남겨놓는 속성들을 말한다.
이번에 사용할 데이터는 'iris (붓꽃) 데이터'이다.
orange에서 추출한 파일의 확장자는 ".tab "

붓꽃 이름 항목이 바로 class이다. 그리고 그 옆에 데이터들이 연속형 변수들 continous

세 가지 붓꽃 종류에 대해서 살펴보자.
꽃잎의 길이와 너비, 꽃받침 길이 너비를 가지고 이 세가지 중에서 어디에 속하는지 분류한다.
Setosa:
Versicolor:
Virqinica:

4개의 feature가 있고 한 개의 target이 있다.
target은 3개의 값을 가지고 있고, 4개의 feature, 150개의 instances
meta data는 없음.
* meta data : 설명 데이터 ex) 변수의 저장 위치 등

산점도를 살펴보면 가로축은 꽃잎의 길이이고, 세로축은 꽃잎의 너비이다. 꽃잎이 더 꽃의 종류와 관련이 있을지 꽃받침이 더 꽃의 종류와 관련이 있을지 예측해볼 수 있다.
Axis x: 는 가로 축, Axis y:는 세로축으로 여기서는 꽃잎의 너비를 x, 꽃잎의 높이를 y축으로 설정하였다.
color는 iris로 타겟값에 따라서 구별이 되어 있고, 모양도 다르게 선택할 수 있다.

label을 변경하면 안에 점들의 사이즈도 값에 따라 다르게 만들 수 있다.

이런 식으로 label도 붙힐 수 있다.

dataset위젯에서 제공하는 오렌지에서 제공하는 tab형식의 데이터를 읽어왔지만, 우리들은 파일위젯을 통해서 다른 곳에서 다운로드 받은 csv형식이나 excel파일 형식의 데이터를 읽어올 수 있다. 그리고 여기서 role도 지정해줄 수 있다. iris데이터는 굉장히 흔한 데이터라서 우리들이 쉽게 구할 수 있다.
이제는 모델을 구성해본다.

여러가지 모델을 구성하고 test and score를 실행해보자

이렇게 모델들을 test and score에 연결했는데도 아무 결과도 나오지 않았다.
이는 data를 test and score에 연결해주지 않아서 그렇다.

이렇게 datasets을 test and score에 연결을 해줘야 에러가 사라진다.

이러면 각 분류기들의 성능 측정 값을 보여준다.

마우스 오른쪽 버튼을 누르면 다른 측정값도 확인할 수 있다.

다 비슷비슷한 성능을 보이지만, 이 중에서 로지스틱 회귀분석이 가장 나은 성능을 보여준다.
위 값들은 실행할때마다 값들이 달라질 수 있다. because 랜덤하게 샘플링해서 학습을 해서 매번 결과가 달라진다.
아래에는 각 모델의 비교값들은 나오지 않고 있다. 이 비교값들은 Cross validation을 할때만 나온다.

수치가 방금전과 달라졌지만 그래도 로지스틱 회귀 모형이 가장 나은 것을 확인할 수 있다.

이 부분은 모델을 서로 비교를 하는건데, auc라는 값에 따라서 비교를 하는 것 *auc: area under ROC curve
이것을 가지고 비교했을때, 행에 있는 모델들이 열에 있는 모델들에 비해서 상대적으로 내부 수치만큼 낫다 라는 의미
ex) random forest가 knn보다 57.8% 낫다.
knn이 random forest에 비해서 42.2% 낫다.
분류에 사용되는 평가지표(AUC, CA, F1, Precision, Recall)

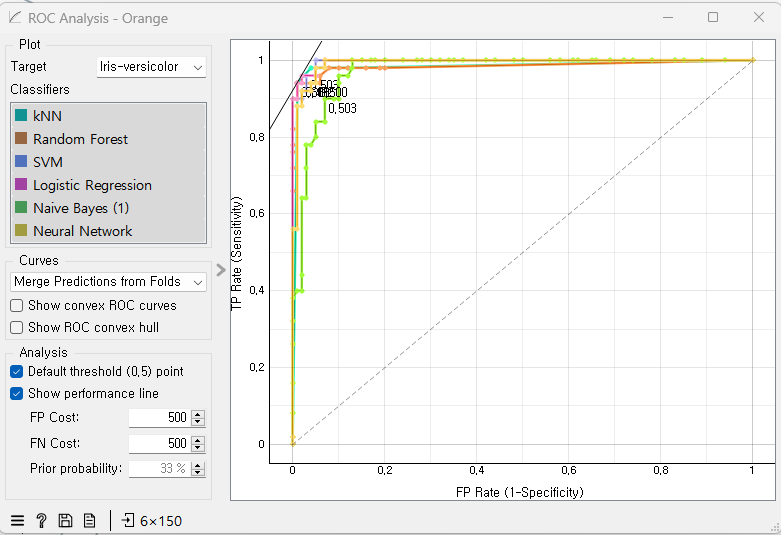
구별은 잘 안되지만 각각의 모델들에 대해서 커브를 그려준 것이고, AUC라고 하는 것이 해당 Curve의 아래 면적이다.
전체 면적이 1에 가까울 수록 성능이 좋아짐
혼동행렬도 연결해보자.

진한 보라색으로 표시된 부분은 에를 들어서 실제로는 sectosa인데, predicted 즉, sectosa라고 에측된 것이 50개이다.
sectosa는 다 맞춤.
그리고 두 번째 줄은 실제로는 버시컬러인데, 예측이 버시컬러는는 47개, 버지니카는 3개 이다.
그리고 세 번쨰 줄은 실제로는 버지니카인데, 버시컬러라고 에측한 것은 1개, 버지니카라고 에측한 것은 49개이다.
여기서 test and score가 두 가지 역할을 함을 확인할 수 있다. 첫 번쨰는

evaluation results target으로 성능의 결과를 알 수 있는 표를 생성해주는 것.
그리고 roc curve, confusion metrics와 같이 클래식 바이어에 성능을 분석하기 위한 다른 위젯에 입력값을 제공한다.
우리는 AUC, CA, F1, Prec, Recall, MCC, ROC에 대해서 살펴본다.

정밀도(Prec) : 혼동 모델에서 실제와 예측값이 맞는 것의 비율 ex) 실제로도 true인데, 에측값도 true일때
재현율: 실제 true인 것 중에 모델이 true라고 에측한 것의 비율
정확도(ca, accuracy): 전체 중에서 실제와 에측이 맞을 비율
F1 Score: precision, recall의 조화평균
fall-out: 실제 false 인 data 중에서 모델이 true라고 에측한 비율
ROC curve: x축에는 fpr값이 들어가고 y축에는 tpr(recall)값이 들어간다. 값이 1에 가까울 수록 좋은 성능을 보인다.
위의 모든 지표들은 1에 가까울 수록 좋은 성능을 보인다.
'Orange3' 카테고리의 다른 글
| Tree 위젯과 Tree View 위젯 (0) | 2023.08.01 |
|---|---|
| 수치형 데이터 - 지도학습(회귀) (1) | 2023.07.31 |
| Orange3 실행 환경 구성 (0) | 2023.07.31 |