지도학습(회귀): 선형회귀모델
1. 파일 위젯을 끌여다가 더블클릭




Data Table을 이용하면 file의 데이터 모양을 확인할 수 있다.
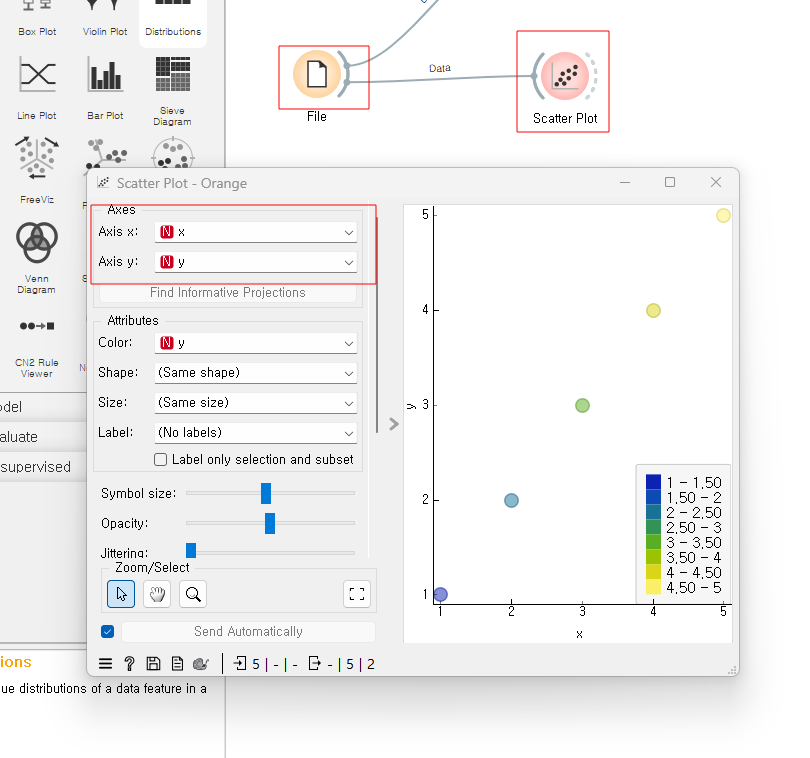
파일에 저장된 데이터의 산점도도 확인할 수 있다.
선형회귀도 확인한다.
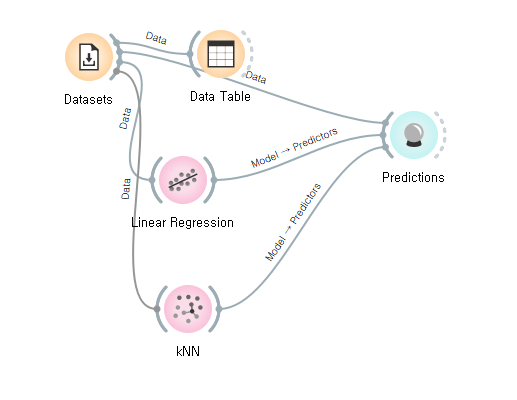
선형회귀 모델에 들어가는 데이터는 아까 우리가 만든 train.csv데이터이고, 클릭하면



위 전체적인 의미는 train데이터를 가지고 선형 회귀를 시행했을떄, 그렇게 생성된 모델에 새로운 데이터를 넣으면 어떤 결과가 나올지 연결을 하는 것

우리는 이미 예측값이 무엇인지 알고 있지만, 이것을 다시 시각화해서 살펴본다.


predictions에서 나오는 값을 산점도에 넣어주면 결과를 시각적으로 확인할 수 있다.



입력값이 binary형태로만 받는 베이즈 모델의 경우는 이산형 변수 데이터를 가진 train데이터를 받아들일 수 없어서 x표시가 나온다.
<정리>
1. file(train), data table, scatter plot은 2-3단계인 데이터 수집/ 데이터 관찰 및 정제에 해당하는 위젯
2. linear regression 은 4단계 머신러닝 모델 설정 및 학습에 해당하는 부분
3. file(test), predictions는 5단계 테스트 데이터 입력 및 예측에 해당하는 부분
보스턴 주택가격 예측
orange에서 제공하는 데이터 셋을 가지고 주택 가격 예측
orange에서 데이터 셋을 가져온다.

주택 가겨들을 테이블 형태로 살펴본다,

506개의 인스턴스(행)들이 있고, 결측치는 없다. 열은 13개, 결과값은 수치형이다.
metadata attribute는 없음. 회색 바탕값은 목표값이다.
우리는 회색바탕 외의 값들을 가지고 이 목표 값(target)을 예측한다. 우리는 이 값을 target이라고 하고 그 외는 feature이라고 한다.
feature → 독립변수
target → 종속(반응)변수
* metadata attribute는 참고 데이터를 말함. (ex) 위치 데이터)
모든 feature을 사용해서 종속변수(중앙값)를 예측해본다.


원래 데이터에서 중앙값을 24로 했던것을 선형회귀는 30으로 예측하였고, 원래 중앙값은 21.6인데, 중앙값이 25로 선형회귀는 예측을 하였다.
예측이 그렇게 잘 된것 같지 않으니 다른 머신러닝 모델을 대입해보기로 한다.

선형회귀 모형보다 좀 더 예측을 잘하였지만, 여전히 좀 부족한 ,...?



Adaboost..? 처음들어보았다...
adaboost가 타겟값과 가장 근접한 알고리즘이다.
100%일치하는 모습을 확인할 수 있다.

predictions에 맨 아래에 있는 값만 가지고도 어떤 것이 문제를 해결하는데 가장 적합한지 알 수 있다.
MSE, RMSE, MAE는 0에 가까울 수록 좋은 성능을 가지고 있고, R2는 1에 가까울 수록 좋은 성능을 가진다.
평가지표
예측값과 실제값이 차이가 적을 수록 예측을 잘 하였음을 의미

MSE, MAE가 무엇인가???
MSE(mean square error): 0에 가까울수록 BEST / 예측값과 실제값의 차이의 제곱을 평균낸 것
즉 분산을 평균낸 것

ex) 예측값과 실제값을 각각 모두 빼면 0이 나온다. 그래서 이를 보정하기 위해서 즉 순수한 각 차이만을 알기 위해 제곱을 해주어 평균을 낸 값이다.
MAE(mean absolute error): 0에 가까울수록 BEST /
ex) MSE는 제곱을 하였지만, 여기선 각 값들을 빼고 절대값을 씌워서 -를 보정해준다.
RMSE(Root mean square error): 0에 가까울수록 BEST / MSE의 내용과 같음 다만 이건 표준편차를 평균낸 것이다.
R2(결정계수) : 모형이 얼마나 적합한가?? 1에 가까울 수록 BEST / x가 y에 얼마나 영향을 끼치는가? (제곱이라서 양수 값만 가짐)
ex) R^2가 0.52이면 X에 의해서 Y가 52%영향을 미친다.

* MAE는 왜 절대값을 사용하였는가???
해당 그래프에서는 실제값들은 예측값을 중심으로 + 방향으로 멀어질 수 있고, -방향으로 제 각각 멀어져 있다. 하지만 우리는 얼마나 떨어져 있는지만 궁금해서 절대값을 취해서 실제 거리만 구하기 위함이다.
* MSE: 제곱을 했다는 의미는 예측값들로부터 거리를 제곱을 하여서 예측값으로부터 멀리 떨어지면 떨어질 수록 벌점을 주어서 더 많이 떨어진 것처럼 보이게 만들 수 있다. 멀리 떨어진 것들은 더 가깝게 붙게끔 만들어줄 수 있다.
* 결정계수: 실제 데이터에 상대적으로 얼마나 가까이 있는지? 비율을 계산한 것
아주 근접하다면 결정계수는 1에 가까워 진다. 결정계수의 장점은 실제 데이터 단위(CM, M, TB등등)에 상관없이 상대적인 값들을 찾아낸다. 이것도 완전히 정확하진 않아서 수정된 결정계수라는 것도 있음.
아 글쓴거 ...날라갓다...
오늘은 도저히 못해...내일해야긋다
다시 시작 이 고물같은 노트북 바꿔주오
Test and Score

위젯 한 개를 가져다 놓으면 그 순간에 데이터를 읽어오고 학습하는 과정이 진행된다.

위 표를 보면 여러 모델들 중 ada boost가 가장 근사한 값을 가지는데,
*ada boost알고리즘이란? 부스팅 알고리즘 중 하나로 adaptive boost의 준말로 부스팅은 약한 모형(weak learner)를 이용하여 강한 모형(strong learner)을 만들어내는 것이 특징인 알고리즘을 말한다. Adaboost는 초기 모형을 아주 약한 모형으로 설정한 뒤 매 step마다 이전 모형의 약점을 보완하는 새로운 모형을 순차적으로 적합
원리: 초기 모형은 약한 모형으로 설정하여 매 step마다 가중치를 이용하여 모형의 약점을 보완하는 새로운 모형을 순차적으로 적합한 뒤 최종적으로 이들을 선형 결합하여 얻어진 모형을 생성시키는 알고리즘

ada boost와 같은 결과가 나온 이유는 무엇인가???
학습에 사용된 데이터와 예측에 사용된 데이터가 서로 완전히 달랐다.

데이터셋을 훈련 데이터와 테스트 데이터로 나뉜다. 훈련 데이터를 가지고 학습을 하고 테스트 데이터를 가지고 평가를 한다. 이전 예제에서는 이 테스트 데이터를 에측하는데 사용했다. 이것은 우리들이 만약에 문제 은행을 보고 문제 은행 안에 있는 문제들을 달달 외워서 시험을 봤다고 생각해보면 당연히 문제를 달달달 외웠으니 시험을 잘 볼 수 밖에 없다.
그것이 바로 같은 데이터 셋 안에 있는 문제들을 가지고 학습을 한 후에 같은 문제들 안에 있는 문제들을 시험 문제로 낸 것과 마찬가지이다. 그러니 당연히 성적이 좋을 수 밖에 없다.
두 번째 예시로는 우리가 교과서를 가지고 열심히 공부를 해서 수능을 보았다. 수능 시험은 교과서에 있는 문제들에서 나오니 공부를 열심히한 학생들은 좋은 성적을 받을 것이고, 공부를 열심히 하지 않은 학생들은 좋은 성적을 받지 못할 것이다. 이것이 바로 train과 test데이터로 나누는 이유이다.
Data set을 training set / test data로 나눠서 수행해보겠다.

test and score 위젯에는 우선 데이터가 들어가야 한다. 그리고 우리가 학습과 테스트를 진행할 모델과 연결을 해야 한다. 그래서 ada boost 한 개만 연결을 해본다.
adaboost에는 세 가지 입력이 들어올 수 있다. → train data, test data, 학습 알고리즘

훈련 데이터가 30%라는 것은 506개의 전체 데이터 중에서 훈련 데이터를 151.8개의 데이터를 훈련 데이터로 놓겠다. train set size는 조정이 가능하다. 조정해보고 가장 정확한 모델 사이즈를 선택하면 된다.
repeat train / test는 10으로 설정되어 있는데, 이는 전체 절차를 10번 반복함을 의미한다.

leave one out은 학습이 느리게 진행되는데, 이는 하나만 남겨두겟다. 이것은 test 를 위한 한 개의 instance만 남겨두고 나머지는 모두 train에 사용하겠다. 즉, 506개 중에 505개를 가지고 train을 하고 하나를 가지고 test를 한다. 이 작업을 각각의 인스턴스마다 즉 506번 반복을 하겠다는 것을 의미한다. 그래서 매우 느린 대신에 안정적이고 결과도 신뢰할 수 있는 결과가 나온다.

test on train data를 살펴보면, predictions와 일치하는 모습을 확인할 수 있다.
이 경우는 train data를 다시 test데이터 사용한경우이다. 즉 train data를 가지고 그대로 TEST를 하겠다는 것이라서 두 개의 결과가 비슷하게 나올 수 밖에 없고, 성능이 매우 좋은것처럼 나오는데 진짜 성능이 좋은지는 알 수 없음.
이건 시험 전에 시험 문제를 달달달 외워서 쓰는 것과 같은 것으로 외우기만해서 역량이 올라가는 것은 아니기 때문

Test on test data를 클릭하면 missing~이러면서 경고메시지가 뜨는데, 별도로 분리된 테스트 데이터 입력 값이 없다라는 의미이다. test on test data를 체크하기 위해서는 기존 housing data는 train에 사용하고 새로운 file데이터를 만들어서 test데이터로 하여 test and score에 연결한다.



validation set와 train set를 따로두고 train set를 가지고 훈련을 한 다음에 validation set를 가지고 검증을 한다.
train은 우리들이 교과서를 가지고 열심히 공부를 하고 valid는 모의고사를 치루는 것. 그러면 그 동안 우리들이 얼마나 공부를 잘 했는지에 대해서 평가를 할 수 있다. 그리고 모의고사는 한 번만 치루는 것이 아니라 여러번 치룬다. 이런 개념이 바로 k fold cross validation,
여기서 k=5, k는 train data를 k개로 나뉘겟다는 의미.
k= valid의 개수 또는 한 줄당 train + valid의 개수
4개의 구간은 train하는데 사용되고 1개의 valid는 검증하는데 사용된다.
두번째 행은 두 번째 구간은 이번에는 검증하는데 사용하고 나머지는 train에 사용한다.
세번째 행은 세 번째 구간을 검증하는데 사용하고 나머지는 train에 사용한다.
이러한 과정을 거치는 것이 k fold cross validation(교차검증)이라고 한다.

orange에서 cross validation이라고 하는 것은 k fold cross validation을 의미.
number of folds는 10이라고 나와있는데, 즉 k=10이고, 이는 train data 506개를 10개로 나누어서
fold값을 얼마로 조정할지는 자유이다.
왼쪽에 메뉴바들을 여러 가지를 바꾸어서 수행을 해보고 그 중에 결과가 좋은 것을 택하면 된다.


여기에 다른 알고리즘을 추가하여 알고리즘간에 성능을 비교할 수 있다.
데이터 테이블에 알고리즘 성능과 결과값들을 비교해볼 수 있다.

test and score를 클릭하여 측정 항목에서 오른쪽 버튼을 누르면 다른 평가지표도 있음을 확인할 수 있다.
* train time = 초 단위로 모델 Train에 사용된 누적 시간을 보여준다.
* test time = 초 단위로 모델 test에 사용된 누적 시간을 보여준다.
* CVRMSE = 실제 값의 평균값으로 정규화된 RMSE 값을 보여준다. 여기에서는 모델을 서로 비교해볼 수 있는데, 이것은 교차검증일때만 비교가 가능하다. 여기서는 모델들이 다른 모델들에 비해서 어느정도 성능이 좋을 것인가 라는 확률값을 제공한다.
'Orange3' 카테고리의 다른 글
| Tree 위젯과 Tree View 위젯 (0) | 2023.08.01 |
|---|---|
| 수치형 데이터 다루기 - 지도학습(분류) (0) | 2023.08.01 |
| Orange3 실행 환경 구성 (0) | 2023.07.31 |